
前言
接口基本结构
{ "key": "例子",
"name": "例子┃BPQ",
"type": 3,
"api": "csp_XBPQ",
"ext": {
"分类url":"电影网站网址/vodshow/{cateId}-{area}-------{catePg}---{year}.html",
"分类":"电影$1#美剧$2#日剧$4#韩剧$3#泰剧$5#动漫$6" }
},这部分就是针对电影网站的配置,其他部分如果没有特殊需求可以基本不用动,稍微懂一点代码的同学应该懂{}中代表的是元素,那么元素该如何获取呢?
其实接口内的jar包内内置很多常用模板,有时候我们直接找到上面两个元素就可以直接上接口食用!
分析编写
那么现在就开始解释下上面的两个元素怎么获取!目标网站网址如下: aHR0cHM6Ly93d3cuenh6amhkLmNvbS8= (base64转码后可看到网址)
- 转码后打开网站
- 进入主页
- 点击电影
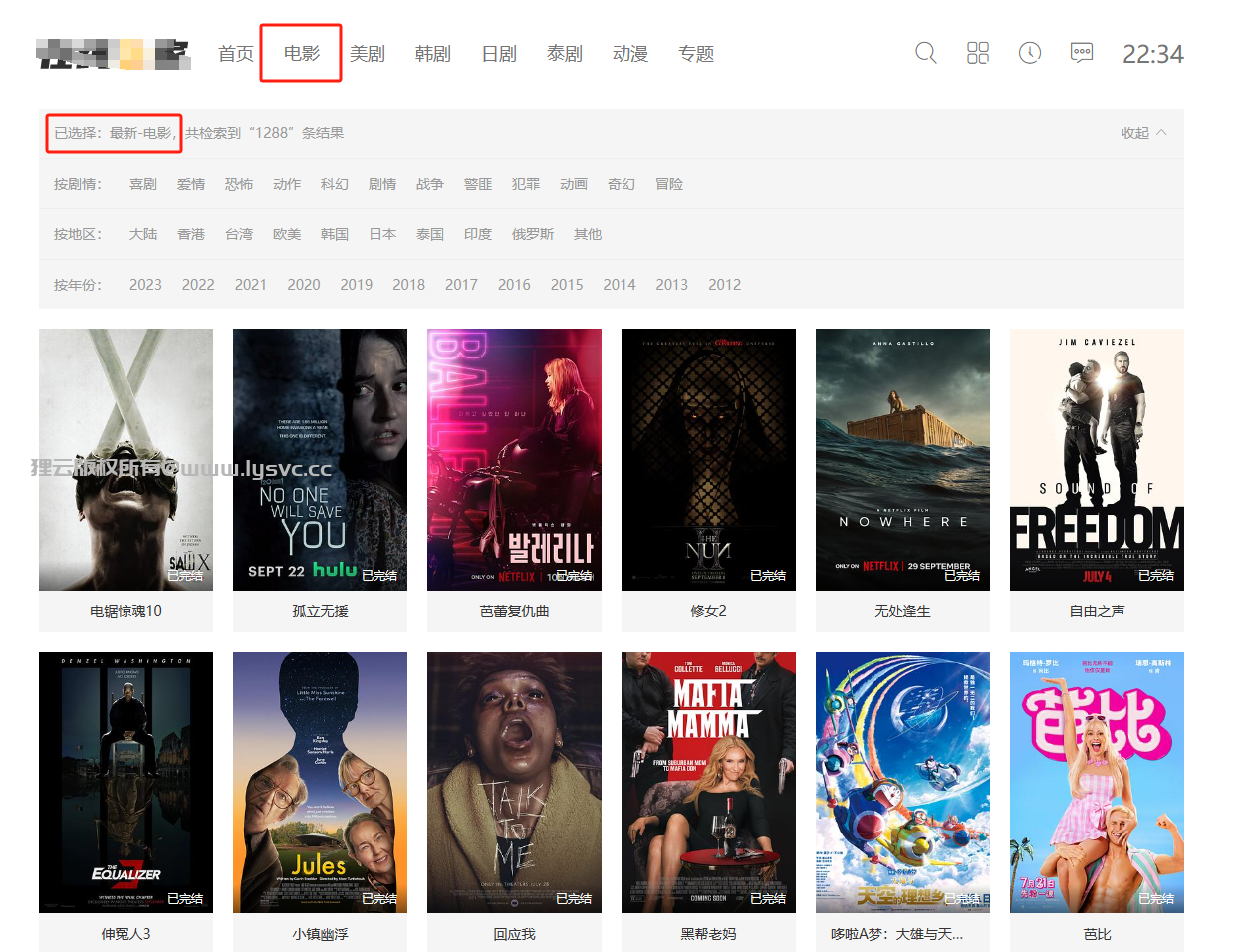
- 进入到这一步后点击年份里的任何一个年份,地区里面的任何一个地区
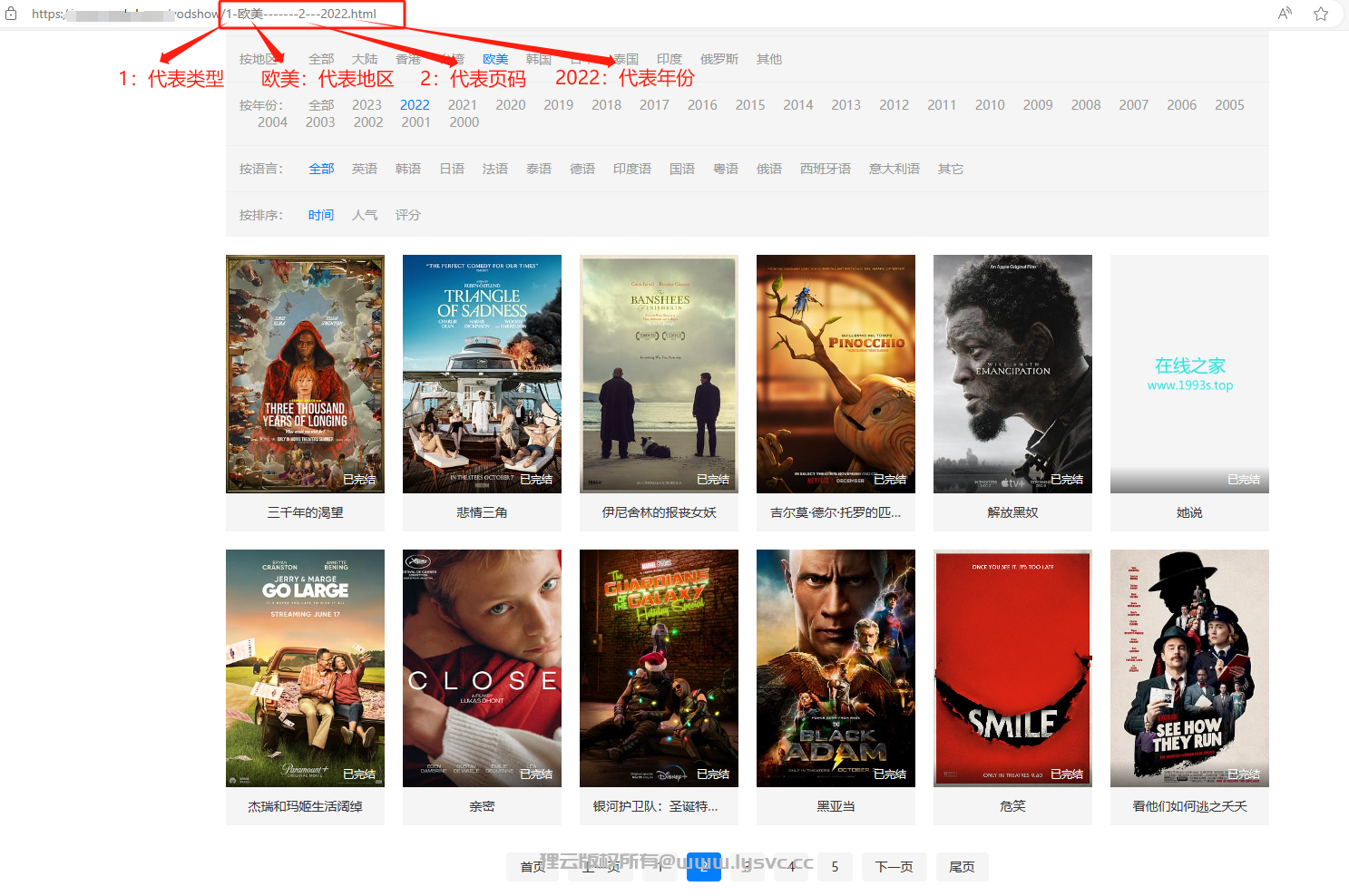
- 复制顶部的文本字样
https://XX.XX.com/vodshow/1---%E7%88%B1%E6%83%85--------.html这一步目的是找到地区、年代在网页地址的排序顺序!这个很重要顺序不能打乱,必须按照网址内容来!
- 替换关键词:
重点注意{cateId}替换的含义!在一个图,小编已经标明了网址中的字符的含义,从中得知,1代表的影片类型,而这个1在网站中代表是:电影,根据这个思路,我回去网站依次点击韩剧,美剧,动漫等,把对应的数字记录下来,如下:1→电影2→美剧3→韩剧4→日剧5→泰剧6→动漫
- {cateId}可以理解为这些数字的占位符,也就是用源码里面的123456("分类":"
电影$1#美剧$2#日剧$4#韩剧$3#泰剧$5#动漫$6" )去填充{cateId}!
如果还看不懂就无脑替换!基本通杀90%网站,
- 替换完形成如下内容!
注意:XX替换网站地址!https://XX/vodshow/{cateId}-{area}-------{catePg}---{year}.html
- area代表地区 catePg代表页码 year代表年代 无脑按照我写的例子做替换!
这样的话我们就搞定了分类URL和分类的内容,其他的内容基本不用动,只需要把电影网站的名称盖上去就OK了
"分类url":"电影网站网址/vodshow/{cateId}-{area}-------{catePg}---{year}.html",
"分类":"电影$1#美剧$2#日剧$4#韩剧$3#泰剧$5#动漫$6" }这个数据上文提到了根据结果来看,可以直接使用!注意电影和填充字中间要用$隔开!
{ "key": "在线之家",
"name": "在线之家┃BPQ",
"type": 3,
"api": "csp_XBPQ",
"ext": {
"分类url":"电影网站网址/vodshow/{cateId}-{area}-------{catePg}---{year}.html",
"分类":"电影$1#美剧$2#日剧$4#韩剧$3#泰剧$5#动漫$6" }
},上接口测试!!!完美输出!
评论(0)